
이론공부
자료구조 - 해쉬 테이블(hash table)
DJ.Kang
2024. 3. 16. 22:57
해쉬 테이블(hash table) : 키(Key)에 데이터(Value)를 저장하는 데이터 구조
- 장점
- 데이터 저장/읽기 속도가 빠르다. (검색 속도가 빠르다.)
- 해쉬는 키에 대한 데이터가 있는지(중복) 확인이 쉬움
- 단점
- 일반적으로 저장공간이 좀더 많이 필요하다.
- 여러 키에 해당하는 주소가 동일할 경우 충돌을 해결하기 위한 별도 자료구조가 필요함
- 주요 용도
- 검색이 많이 필요한 경우
- 저장, 삭제, 읽기가 빈번한 경우
- 캐쉬 구현시 (중복 확인이 쉽기 때문)

- for i in range(10)은 반복문입니다. 이것은 0부터 9까지의 정수를 순회하는 반복문입니다. 이 코드는 각 숫자를 반복하는 데 사용되며, 순회되는 숫자는 변수 i에 할당됩니다.
- i for i in range(10)은 리스트 컴프리헨션입니다. 이것은 0부터 9까지의 정수를 순회하면서 각 숫자를 새로운 리스트에 추가하는데 사용됩니다. 즉, 이 코드는 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]와 같은 리스트를 생성합니다.
□ 충돌(Collision) 해결 알고리즘
- Chaining 기법
- 개방 해슁 또는 Open Hashing 기법 중 하나 : 해쉬 테이블 저장공간 외의 공간을
활용하는 기법
- 충돌이 일어나면, 링크드 리스트라는 자료 구조를 사용해서, 링크드 리스트로
데이터를 추가로 뒤에 연결시켜서 저장하는 기법
- Linear Probing 기법
- 폐쇄 해슁 또는 Close Hashing 기법 중 하나 : 해쉬 테이블 젖아공간 안에서 충돌 문제를
해결하는 기법
- 충돌이 일어나면, 해당 hash address의 다음 address부터 맨 처음 나오는 빈공간에 저장하는
기법 → 저장공간 활용도를 높이기 위한 기법

- 빈번한 충돌을 개선하는 기법
□ 해쉬 테이블의 시간 복잡도
- 일반적인 경우(Collision이 없는 경우)는 O(1)
- 최악의 경우(Collision이 모두 발생하는 경우)는 O(n)
해쉬 테이블의 경우, 일반적인 경우를 기대하고 만들기 때문에, 시간 복잡도는 O(1) 이라고 말할 수 있음
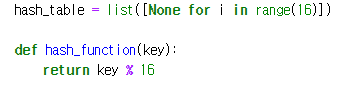
검색에서 해쉬 테이블의 사용 예
- 16개의 배열에 데이터를 저장하고, 검색할 때 O(n)
- 16개의 데이터 저장공간을 가진 위의 해쉬 테이블에 데이터를 저장하고, 검색할 때 O(1)
□ 해쉬 함수와 키 생성 함수
- 파이썬의 hash() 함수는 실행할 때마다, 값이 달라질 수 있음
- 유명한 해쉬 함수들이 있음: SHA(Secure Hash Algorithm, 안전한 해시 알고리즘)
- 어떤 데이터도 유일한 고정된 크기의 고정값을 리턴해주므로, 해쉬 함수로 유용하게 활용 가능
1. SHA - 1

2. SHA - 256
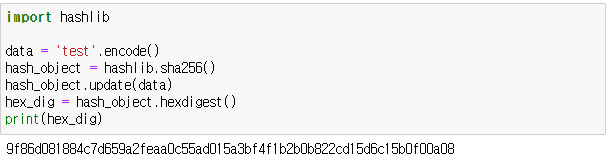
※ hex_dig 의 경우 문자열(str)이므로 해쉬 함수(ket % n)실행 불가,
숫자로 변환(int)시켜 줘야함
